




바이트 저장 순서
비트(bit)와 바이트(byte)
컴퓨터는 모든 데이터를 2진수로 표현하고 처리합니다.
비트(bit)란 컴퓨터가 데이터를 처리하기 위해 사용하는 데이터의 최소 단위입니다.
이러한 비트에는 2진수의 값(0과 1)을 단 하나만 저장할 수 있습니다.
바이트(byte)란 위와 같은 비트가 8개 모여서 구성되며, 한 문자를 표현할 수 있는 최소 단위입니다.
바이트 저장 순서(byte order)
컴퓨터는 데이터를 메모리에 저장할 때 바이트(byte) 단위로 나눠서 저장합니다.
하지만 컴퓨터가 저장하는 데이터는 대게 32비트(4바이트)나 64비트(8바이트)로 구성됩니다.
따라서 이렇게 연속되는 바이트를 순서대로 저장해야 하는데, 이것을 바이트 저장 순서(byte order)라고 합니다.
이때 바이트가 저장되는 순서에 따라 다음과 같이 두 가지 방식으로 나눌 수 있습니다.
1. 빅 엔디안(big endian)
2. 리틀 엔디안(little endian)
빅 엔디안(big endian)
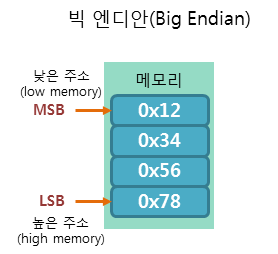
빅 엔디안 방식은 낮은 주소에 데이터의 높은 바이트(MSB, Most Significant Bit)부터 저장하는 방식입니다.
이 방식은 평소 우리가 숫자를 사용하는 선형 방식과 같은 방식입니다.
따라서 메모리에 저장된 순서 그대로 읽을 수 있으며, 이해하기가 쉽다는 장점을 가지고 있습니다.
SPARC을 포함한 대부분의 RISC CPU 계열에서는 이 방식으로 데이터를 저장합니다.
예를 들어 다음과 같이 저장할 32비트 크기의 정수가 있다고 가정합니다.
예제
0x12345678
이 정수는 각각 다음과 같이 1바이트값 4개로 구성됩니다.
예제
0x12, 0x34, 0x56, 0x78
이 4개의 1바이트 값을 빅 엔디안 방식으로 저장하면 다음 그림과 같이 저장됩니다.
리틀 엔디안(little endian)
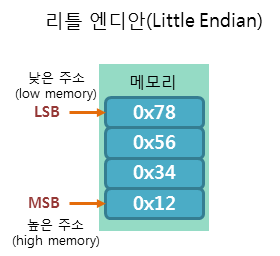
리틀 엔디안 방식은 낮은 주소에 데이터의 낮은 바이트(LSB, Least Significant Bit)부터 저장하는 방식입니다.
이 방식은 평소 우리가 숫자를 사용하는 선형 방식과는 반대로 거꾸로 읽어야 합니다.
대부분의 인텔 CPU 계열에서는 이 방식으로 데이터를 저장합니다.
앞서 예를 든 정수 "0x12345678"를 리틀 엔디안 방식으로 저장하면 다음 그림과 같이 저장됩니다.
빅 엔디안 vs 리틀 엔디안
빅 엔디안과 리틀 엔디안은 단지 저장해야 할 큰 데이터를 어떻게 나누어 저장하는가에 따른 차이일 뿐, 어느 방식이 더 우수하다고는 단정할 수 없습니다.
물리적으로 데이터를 조작하거나 산술 연산을 수행할 때에는 리틀 엔디안 방식이 더 효율적입니다.
하지만 데이터의 각 바이트를 배열처럼 취급할 때에는 빅 엔디안 방식이 더 적합합니다.
현재 여러분이 사용하는 대부분의 시스템은 인텔 기반의 윈도우이므로 리틀 엔디안 방식을 사용하고 있을 것입니다.
하지만 네트워크를 통해 데이터를 전송할 때에는 빅 엔디안 방식이 사용됩니다.
따라서 인텔 기반의 시스템에서 소켓 통신을 할 때는 바이트 순서에 신경을 써서 데이터를 전달해야 합니다.
바이트 저장 순서의 확인
다음 예제를 실행하면 여러분의 시스템에서 사용하고 있는 바이트 저장 순서를 확인할 수 있습니다.
예제
int i;
int test = 0x12345678;
char* ptr = (char*)&test; // 1 바이트만을 가리키는 포인터를 생성함.
for (i = 0; i < sizeof(int); i++)
{
printf("%x", ptr[i]); // 1 바이트씩 순서대로 그 값을 출력함.
}
실행 결과
78563412
위의 예제 결과가 '78563412'로 출력되었다면 리틀 엔디안 방식의 시스템일 것입니다.
만약 예제의 결과가 '12345678'로 출력되었다면 빅 엔디안 방식의 시스템일 것입니다.
