




딥러닝의 역사
딥러닝의 겨울
1957년 프랑크 로젠블라트(Frank Rosenblatt)가 퍼셉트론 이론을 발표한 이래 인공신경망 이론은 효과적인 학습 모델을 찾지 못한 채 여러 가지 문제에 직면하게 됩니다.
역전파(backpropagation)법에서 인공신경망의 레이어(layer)가 늘어날수록 오래 전 데이터에서 기울기가 사라지는 문제(vanishing gradient problem)와 학습 데이터를 과하게 학습하여 학습 데이터에 대해서는 오차가 감소하지만 실제 데이터에 대해서는 오히려 오차가 증가하는 과적합(overfitting) 문제, 마지막으로 문제의 규모가 커질 때마다 나타나는 높은 시간 복잡도와 컴퓨터 성능의 한계 등으로 인해 인공신경망 이론은 큰 진전을 보지 못하고 정체 상태를 맞이하게 됩니다.
딥러닝의 부활
2006년 토론토 대학의 제프리 힌튼(Geoffrey Hinton) 교수는 심층 신뢰 신경망(Deep Belief Network, DBN)이라는 딥러닝에 매우 효과적인 알고리즘에 관한 논문을 발표합니다. 제프리 힌튼 교수는 이 논문을 실제 적용하여 2012년 세계 최대 이미지 인식 경연대회인 ILSVRC에서 나머지 팀들이 26% 대의 이미지 인식 오류율로 각축을 벌일 때 홀로 15% 대의 오류율을 기록함으로써 1위를 차지하게 됩니다.
인공지능 분야의 전문가들 대부분은 제프리 힌튼 교수의 이 논문이 딥러닝의 부활을 알리는 계기가 되었다고 말하고 있습니다.
또한, 기울기가 사라지는 문제(vanishing gradient problem)를 해결하기 위해 기존에 사용하던 시그모이드(sigmoid) 함수 대신에 ReLU(Rectified Linear Unit)라는 함수가 새롭게 고안되었으며, 드롭아웃 계층(dropout layer)을 사용하여 학습 중일 때 랜덤하게 뉴런을 비활성화 함으로써 학습이 학습 데이터에 치우치는 과적합(overfitting) 문제를 해결하였습니다.
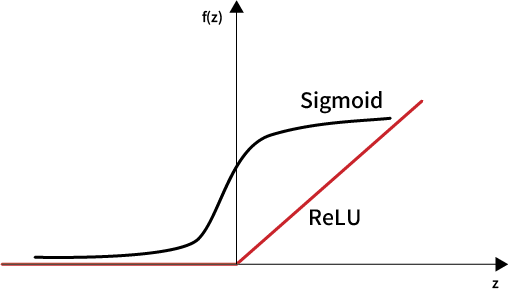
이러한 혁신적인 알고리즘의 개발과 더불어 컴퓨터 하드웨어의 급속한 발달, GPU를 활용한 병렬처리 기술의 개발 등으로 딥러닝은 획기적으로 그 성능이 향상되어 새로운 도약의 시대를 맞이하게 됩니다.
딥러닝의 도약과 그 원동력
딥러닝은 세계경제포럼 선정 2017년도 10대 미래유망기술, IEEE 컴퓨터 협회 선정 2018년도 10대 기술 트렌드 등 미래를 선도할 혁신 기술의 하나로 각광받고 있습니다.
딥러닝이 이렇게 빠르게 발전할 수 있었던 원동력은 다음과 같습니다.
1. GUP 기반의 병렬처리를 포함한 컴퓨팅 파워(computing power)의 발달
2. 인터넷을 통해 축적된 엄청난 양의 빅데이터(big data)
3. 딥러닝을 위한 획기적인 알고리즘의 고안
이 중에서도 빠른 시간 안에 더욱 빠르게 발전할 수 있는 가능성을 가지고 있는 분야는 바로 알고리즘 분야입니다.
