




머신러닝 – 지도 학습
머신러닝의 분류
머신러닝은 학습하려는 문제의 유형에 따라 크게 다음과 같은 세 가지로 분류할 수 있습니다.
1. 지도 학습(Supervised Learning)
2. 비지도 학습(Unsupervised Learning)
3. 강화 학습(Reinforcement Learning)
지도 학습(Supervised Learning)
지도 학습(Supervised Learning)이란 간단히 말해 선생님이 문제를 내고 그 다음 바로 정답까지 같이 알려주는 방식의 학습 방법입니다.
즉, 여러 문제와 답을 같이 학습함으로써 미지의 문제에 대한 올바른 답을 예측하고자 하는 방법입니다.
따라서 지도 학습을 위한 데이터에는 문제와 함께 그 정답까지 함께 알고 있는 데이터가 선택됩니다.
예를 들어, “장미꽃이 찍혀 있는 이미지 데이터”에 레이블로 “해당 장미꽃의 품종을 나타내는 텍스트“를 함께 입력하여 학습기를 지도 학습시키면, 다른 장미꽃이 찍힌 새로운 이미지를 받았을 때 해당 장미꽃의 품종이 무엇인지를 예측할 수 있게 되는 것입니다.
지도 학습 모델
머신러닝에서 지도 학습을 위한 모델은 크게 분류(classification) 모델과 예측(prediction) 모델로 구분됩니다.
분류 모델은 사용하는 알고리즘에 따라 또다시 KNN(K Nearest Neighbor), 서포트 벡터 머신(Support Vector Machine, SVM), 의사결정 트리(decision trees) 등의 모델로 구분되며, 예측 모델로는 회귀(regression) 모델이 대표적으로 사용되고 있습니다.
분류 모델과 예측 모델 모두 지도 학습 모델이므로, 데이터와 레이블을 함께 학습시킨다는 공통점을 가집니다.
하지만 분류 모델은 학습 데이터의 레이블 중 하나가 결괏값이 되고, 예측 모델은 학습 데이터에서 도출된 함수식에서 계산된 임의의 값이 결괏값이 되는 점이 서로 다릅니다.
분류(classification) 모델
분류 모델은 레이블이 달린 학습 데이터로 학습한 후에 새로 입력된 데이터가 학습했던 어느 그룹에 속하는 지를 찾아내는 방법입니다.
따라서 분류 모델의 결괏값은 언제나 학습했던 데이터의 레이블 중 하나가 됩니다.
즉, 다음과 같은 이미지를 통해 학습한 결과 새로운 이미지에 해당하는 숫자가 0인지 1인지를 파악하는 것입니다.
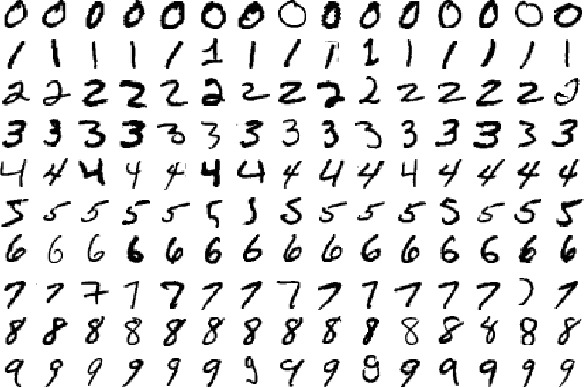
예를 들어, ‘가’, ‘나’, ‘다’라는 레이블이 달린 데이터를 분류 모델로 지도 학습한 후, 새로운 데이터를 분석한 결과는 반드시 ‘가’, ‘나’, ‘다’ 중의 하나가 되는 것입니다.
이러한 유형의 문제는 일상에서 흔히 접할 수 있는 문제이며, 따라서 이에 관한 연구가 많이 진행되어 있습니다. 또한 기업에서도 많은 관심을 가지고 있는 문제 중 하나입니다.
예측 모델(predictive model)
예측 모델도 분류 모델과 마찬가지로 지도 학습 모델이므로 레이블이 달린 학습 데이터로 학습하게 됩니다.
하지만 예측 모델은 분류 모델과는 달리 레이블이 달린 학습 데이터를 가지고 특징(feature)과 레이블(label) 사이의 상관관계를 함수식으로 표현하게 됩니다.
따라서 ‘가’, ‘나’, ‘다’라는 레이블이 달린 데이터를 예측 모델로 지도 학습하였다고 하더라도 분류 모델처럼 결괏값이 반드시 ‘가’, ‘나’, ‘다’ 중 하나가 되는 것이 아니라 해당 범위 내의 어떠한 값도 나올 수 있는 것입니다. 이처럼 어떠한 값이 결과로 나올지 예상할 수 없으므로, 이를 예측 모델이라고 부릅니다.
이러한 예측 모델은 주가나 환율 분석 등과 같이 연속적인 범위 내의 값에서 그 결괏값을 예측하는 문제에 일반적으로 많이 활용됩니다.
