




머신러닝 – 비지도 학습
비지도 학습(Unsupervised Learning)
선생님이 문제와 함께 정답(레이블)까지 알려주는 지도 학습과는 달리 비지도 학습(Unsupervised Learning)은 문제는 알려주되 정답까지는 알려주지 않는 학습 방식입니다. 즉, 여러 문제를 학습함으로써 해당 데이터의 패턴, 특성 및 구조를 스스로 파악하여, 이를 통해 새로운 데이터에서 일정한 규칙성을 찾는 방법입니다.
비지도 학습은 구체적인 결과에 대한 사전 지식은 없지만 해당 결과 데이터를 통해 유의미한 지식을 얻고자 할 때 사용되며, 사람도 제대로 알 수 없는 본질적인 문제나 데이터에 숨겨진 특징이나 구조 등을 연구할 때 많이 활용됩니다.
머신러닝에서 비지도 학습을 위한 모델로는 군집화(clustering)가 대표적입니다.
군집화(clustering)
비지도 학습에 사용되는 데이터에는 레이블(label)이 명시되어 있지 않기 때문에 지도 학습과는 또 다른 방식으로 학습을 수행해야 합니다.
이때 가장 많이 사용되는 방법이 바로 입력된 데이터가 어떤 형태로 서로 그룹을 형성하는지를 파악하는 것입니다.
비지도 학습에서 가장 대표적으로 사용되는 이 모델은 군집화(clustering) 또는 클러스터링이라고 불립니다.
군집화는 레이블이 없는 학습 데이터들의 특징(feature)을 분석하여 서로 동일하거나 유사한 특징을 가진 데이터끼리 그룹화 함으로써 레이블이 없는 학습 데이터를 군집(cluster, 그룹)으로 분류합니다. 그리고 새로운 데이터가 입력되면 지도 학습의 분류 모델처럼 학습한 군집을 가지고 해당 데이터가 어느 군집에 속하는지를 분석하는 것입니다.
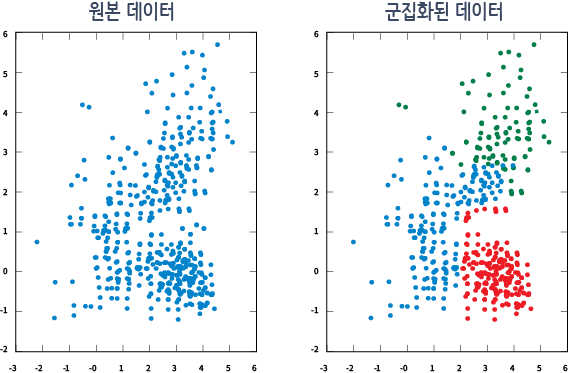
군집(cluster)의 타당성 평가
비지도 학습에 사용되는 데이터에는 레이블(label)이 없으므로, 지도 학습처럼 단순정확도(accuracy)를 지표로 그 정확도를 평가할 수는 없습니다.
즉, 다음 그림과 같이 레이블이 없는 데이터 집합 내에서 최적의 군집 모양과 개수를 파악하기란 굉장히 어렵습니다.
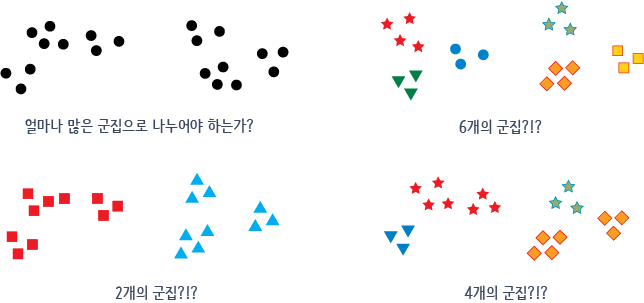
군집을 만든 결과가 얼마만큼 타당한지는 군집간의 거리, 군집의 지름, 군집의 분산도 등을 종합적으로 고려하여 평가할 수 있습니다.
따라서 일반적으로 군집 간 분산(inter-cluster variance)이 최대가 되고 군집 내 분산(inner-cluster variance)이 최소가 될 때 최적의 군집 모양과 개수라고 판단하고 있습니다.
군집화의 분류
군집화의 주목적은 레이블이 없는 데이터 집합의 요약된 정보를 추출하여, 이를 가지고 전체 데이터 집합이 가지고 있는 특징을 찾는 것입니다.
이러한 군집화는 사용하는 알고리즘에 따라 크게 두 가지 기법으로 나눌 수 있습니다.
1. 분할 기법(partitioning methods)의 군집화
2. 계층적 기법(hierarchical methods)의 군집화
분할 기법의 군집화는 각 그룹은 적어도 하나의 데이터를 가지고 있어야 하며 각 데이터는 정확히 하나의 그룹에 속해야 한다는 규칙을 가지고 데이터 집합을 작은 그룹으로 분할하는 방식입니다. 이러한 분할 기법의 군집화에는 k-means, k-medoids, DBSCAN 등의 기법 등이 있습니다.
계층적 기법의 군집화는 데이터 집합을 계층적으로 분해하는 방식으로 그 방식에 따라 또다시 집괴적(agglomerative) 군집화와 분할적(divisive) 군집화로 나눠집니다.
군집화의 활용
군집화는 매우 다양한 분야에서 사용되고 있는 머신러닝 방법으로, 의학 분야에서는 특정 질병에 대한 공간 군집 분석을 통해 질병의 분포 면적과 확산 경로 등을 파악하는 역학 조사 등에서 활용되고 있으며, 홍보 분야에서는 고객을 세분화할 때 군집화를 활용하고 있습니다.
또한, 통계 분야에서도 분석하고자 하는 데이터에 다양한 군집화 알고리즘과 방법론을 사용하여 데이터 분석에 활용해 나가고 있는 추세입니다.
