




딥러닝에서 사용되는 알고리즘
자동 음성 인식
아래 표는 TIMIT 데이터에 대한 자동 음성 인식 결과를 보여준다.
이 데이터셋은 딥 러닝의 초창기 평가를 위한 일반적인 데이터로서, 미국의 8가지 방언을 사용하는 총 630명의 사람이 읽은 10가지 문장으로 이루어져 있다. 데이터의 크기가 작기 때문에 다양한 설정을 효과적으로 적용할 수 있다. 더 중요한 점은 TIMIT에서 음소 순서 인식(phone-sequence recognition)을 고려한다는 점이다.
따라서, 단어 순서 인식(word-sequence recognition)과는 달리 아주 약한 "언어모델"을 허용하고 음성 인식에서의 음향 모델 측면을 더 쉽게 분석할 수 있다.
2009 ~ 2010년 무렵, 크고 작은 범위의 음성인식에 대한 딥 러닝 기술 활용을 위해서 많은 투자가 있었는데, Li Deng과 그의 동료들은 TIMIT에서의 GMM 과 DNN 모델을 비교하는 실험을 수행하였다.
결국 그들은 음성인식에서의 딥 러닝 활용에 있어서 가장 앞서나가게 되었다. 이 분석은 먼저 식별적 DNN과 발생적 모델 사이의 성능 비교(1.5% 이하의 오차율)로 수행되었다.
아래 표에 나타난 오차율은 앞에서 말한 초창기 실험을 포함하여 과거 20 여 년 간 수행된 실험들의 음소 오차율(Phone error rate)을 요약한 것이다.
|
방식 |
PER(%) |
|
Randomly Initialized RNN |
26.1 |
|
Bayesian Triphone GMM-HMM |
25.6 |
|
Hidden Trajectory (Generative) Model |
24.8 |
|
Monophone Randomly Initialized DNN |
23.4 |
|
Monophone DBN-DNN |
22.4 |
|
Triphone GMM-HMM with BMMI Training |
21.7 |
|
Monophone DBN-DNN on fbank |
20.7 |
|
Convolutional DNN |
20.0 |
|
Convolutional DNN w. Heterogeneous Pooli |
18.7 |
|
Ensemble DNN/CNN/RNN |
18.2 |
|
Bidirectional LSTM |
17.9 |
TIMIT로부터 대량 어휘 음성인식(large vocabulary speech recognition)으로의 딥 러닝의 확장은 2010년 산업계 연구자들에 의해 성공적으로 수행되었다.
자동 음성 인식 분야의 2014년 10월까지의 최신 동향은 마이크로소프트 리서치의 책 에 잘 정리되어있다.
또한 자동 음성인식과 관련된 배경 지식과 다양한 기계학습 패러다임의 영향을 잘 정리한 글을 참고할 수 있다.
대용량 자동 음성인식은 최근 딥 러닝의 역사에서 산업계와 학계를 모두 아우르는 처음이자 가장 성공적인 케이스라고 할 수 있다.
2010년부터 2014년까지, 신호처리와 음성인식에 대한 주요 학술회의인 IEEE-ICASSP 와 Interspeech는 음성인식을 위한 딥 러닝 분야의 합격 논문 개수에 있어서 거의 기하급수적인 성장을 보여주었다.
더 중요한 것은, 현재 모든 주요 상업 음성인식 시스템(MS 코타나, 스카이프 번역기, 구글 나우, 애플 시리 등등)이 딥 러닝 기법에 기반하고있다.
|
적용 화자 |
화자 종속 |
미리 등록한 특정 화자 높은 인식 성능 |
휴대폰 보이스 다이얼링 |
|
화자 독립 |
불특정 화자 대용량 음성 DB |
Directoy assistance |
|
|
발음 형태 |
고립어 |
고립 단어 단어 전후에 묶음 존재 |
보이스 브라우저 완구류(임베디드) |
|
연속어 |
연결 단어, 연속 문장, 대화체 다양한 발음 변이를 고려한 언어 모델, 핵심어 인식 |
대화형 자동예약 음성 dictation 증권거래 |
|
|
어휘 크기 |
소용량 |
수백~수천 단어 단어 모델, 문맥 독립형 모델 |
윈도우제어 TV 제어 |
|
대용량 |
수만 단어 이상 문맥을 고려한 sub –word(형태소) 형태의 모델 단위 |
자동 통역 음성 검색 회의 녹취 |
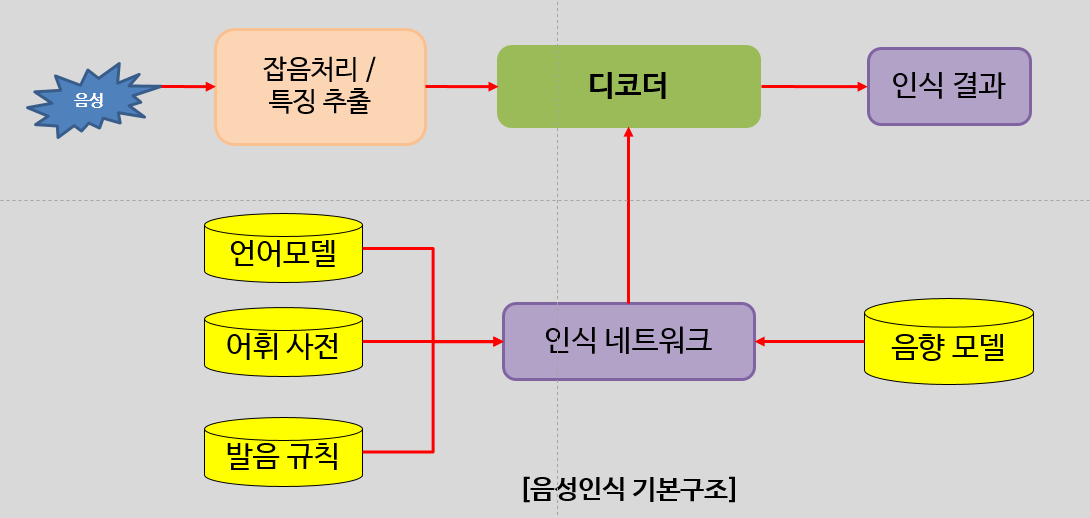
- 자음접변, 구개음화 등의 일반적인 음운 현상을 반영하기 위해 발음규칙이 사용.
- 인식 어휘 자체를 등록하기 위해 어휘 사전 사용.
- 음향모델 측면에서 딥러닝 기술이 매우 효과적.
- 언어모델 측면에서는 그 효 과가 상대적으로 약하게 나타남.
- 딥러닝 및 잡음처리 기술의 발전으로 사람간의 자연스런 대화 음성을 대상으로 기술 고도화 가 이루어지고 있음.
대화체 음성인식이 어려운이유
- ‘그러니까’,‘ 음’,‘ 아참’ 등등 헤아릴 수 없이 많은 간투사가 수시로 사용
- 더듬거 림, 어휘의 도치 현상, 동일 어휘의 반복이나 어휘적 단락(끊어 짐), 재발성 등등으로 인한 비문법적인 비정형 발성이 빈발함 에 기인
- 비정형 자연어(unstructured spontaneous speech)라고로 정의.
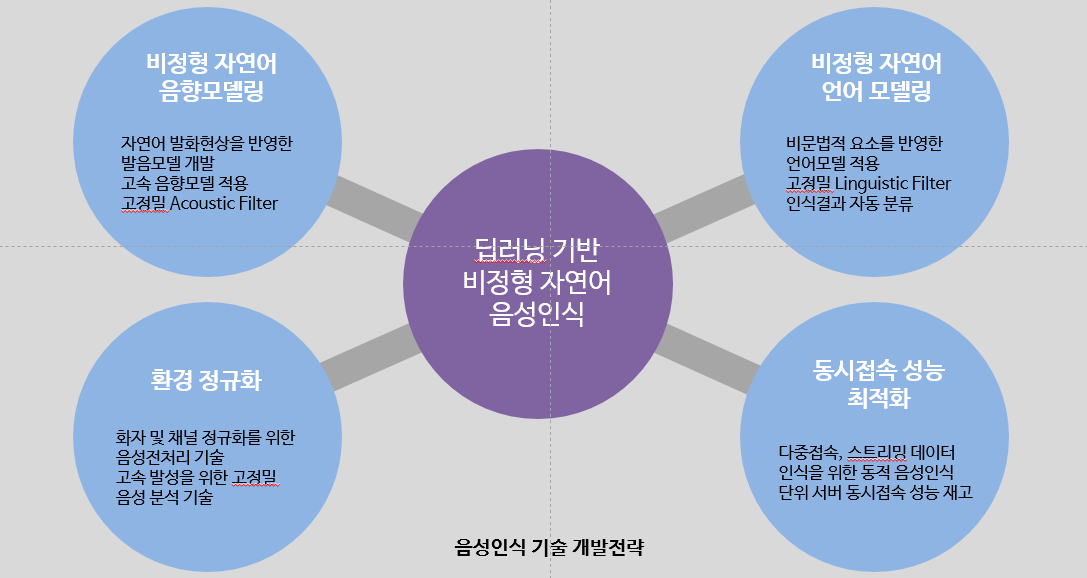
딥러닝 음성인식 기술의 전망
- 학습의 기본 알고리즘 측면에서는 영상, 문자, 음성, 제스처 등 단일한 모달리티(modality)를 독립적으로 학습 및 인식하는 방식에서 나아가 영상이나 음성 등의 여러 가지 모달리티를 동시에 학습 및 인식하는 방식으로 변화할 것.
예) 음성 신호와 입술의 움직임을 동시에 사용해서 고성능 음성인식이 가능하게 되는 것.
- 시간적으로나 공간적으로 분리된 대상(object)을 인식하는 이산형(discrete), 분절형 (segmented) 방법론으로부터 이들을 시간적, 공간적으로 연동해 학습함으로써 인식 성능을 높이는 방향으로 발전하게 될 것.
예) 단순한 정지 영상 또는 그 결합을 인식 대상으로 하지 않고 연속된 영상 자체를 인식하는 동적/증강형 (dynamic/incremental) 학습으로 발전하게 될 것.
- 단순 데이터나 패턴을 분류하는 데서 나아가 대상이 내포하는 의미까지 인지하게 되는 방향으로 발전하게 될 것.
예) 음성 신호에서 특정 어휘를 인식한 다음 단어가 문맥적으로 어떤 의미를 내포하고 있는지, 어떠한 감정이 포 함되어 있는지까지 파악하여 대화를 진행할 수 있게 될 것.
- 향후 이러한 수동 또는 반자동으로 생성되는 지식은 데이터만 주어지면 인공지능이 스스로 학습해서 지식을 쌓아가는 형태인 자율 학습 방법론에 따라 사람의 개입이 최소화되는 방향으로 발전할 전망이다.
- 하나의 지식이 생성되면 유사한 지식을 자가적으로 확장해 나가는 다중도메인 확장 지식, 다양한 지식을 검색하고 분석하는 방식에서 나아가 기존 지식에 기반해서 새로운 사실을 예측해 나가는 예측형 지능으로 발전할 전망이다.
